Jan 2020
An Optimisaiton Journey. Client : Rap Research Lab

Rendering 5000 TextMeshPro meshes in 1ms for an interactive VR word cloud
I started with a naive 5000 TextMeshPro gameobjects, which could take 30ms CPU and GPU, and made a new system that took 1ms CPU and GPU and still looked dope.
Functionality
Interactive 3D visualization of words used in a corpus of rap lyrics (See Part 1)
Interface Features
- Left Thumb button transitions from Globe View to Word Cloud view
- Right hand controller has a “laser” which intersects with words to select them
- Clicking word with laser transports user to the word
- Words can also be selected with Right Hand controller Interaction point
- Selecting word with Right hand shows usage over time of the word and 10 similar words Timeline View
- Pressing both grips allows user to scale and rotate the word cloud.
- Runs in VR at 90fps on mid-tier hardware
Visualization Features
-
- Words are color coded by part of speech
- Words are scaled by frequency of use
- Words are scaled by distance from user
- Words transition into points when they are far away
Implementation
Initial Approach
builtin Unity TextMesh plus a backing quad
5k TextMeshPro components in VR. Added some depth fog for depth perception purposes.


Since premature optimization is the root of all evil, I just did the simplest thing I could think of at first. Instantiate 5000 gameobjects with TextMeshPro on them and it actually worked at 60fps. Add in my two-hand grip trackball I have used from my fractal visualizer to explore and zoom the cloud. The client complained of a “weird shimmery effect when moving” which usually means Oculus time warp. The rendering would hit 30 when looking at every element of the cloud at once which is rare. But, when I started making it interactive it was tough to:
- Manually get the text to face camera (GameObject.transform.LookAt(camera) 5k times)
- Rescale TMP transforms (TextMeshPro does some kind of recalculation on the rescale of a TMP component)
- Move Unity colliders (Causes Unity physics update)
Let’s check out the profiler…
Unity Profiler is tough to read sometimes, so I like to profile the scene with all my non-essential GameObjects disabled to see what we’re working with as a baseline.
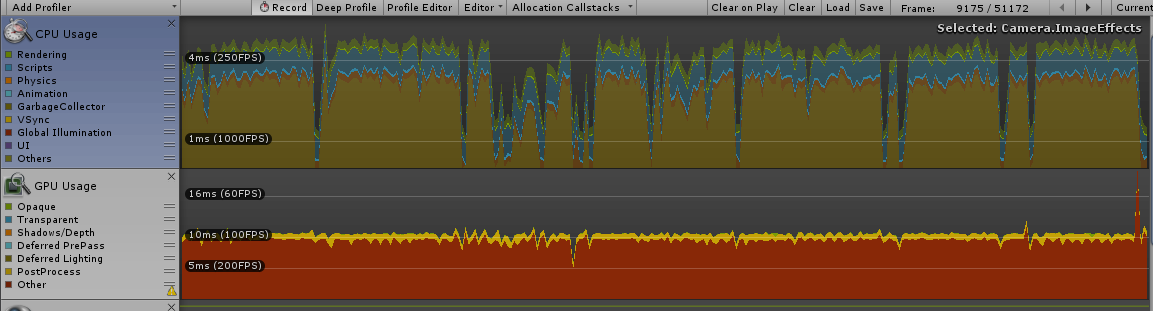
Lot of vsync with the CPU, which is good (CPU and GPU taking < 16ms which is my refresh rate) and then 10ms of Other on the GPU (damn!) which could be Unity Editor overhead, like rendering the profiler or something. Good to know.
Here’s a profile of the first initial version:
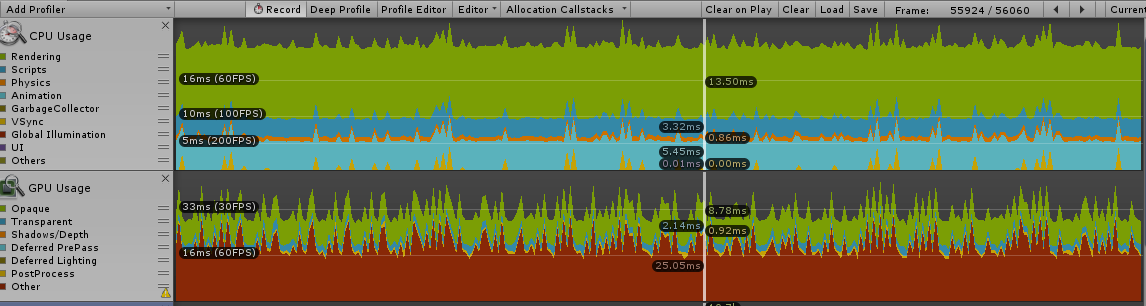
- 13ms for draw calls alone
- 3ms for the script update to make everything look at the camera
- 5ms for animation (not sure what that’s about)
- 9ms on GPU for rendering (not bad, but i have a 2080Ti)
Let’s see why rescaling is so slow:

Clear bump during frames where the Word Cloud is changing scale:
- Rendering / draw calls unchanged
- 17ms scripts (TextMeshPro)
- 7ms physics
Oh ya, by the way there are 10k batches and 100k triangles! That’s no good, looks like my TextMeshPros aren’t batching.
First Optimisation
At this point, I moved the project to “Single Pass” stereo for VR, since that should give me at least a 50% speedup, but the way it handles shaders had caused unexpected issues before. And there is still a bug in Unity’s postprocessing stack “Bloom” effect that doesn’t do a double wide buffer for the bloom downsample pass, which required me to just jump in and multiply the bloom buffer width by 2. I reported this bug about two years ago ¯_(ツ)_/¯
Next idea was to disable TextMeshPro renderers if they are beyond a certain distance from the camera. This will cut down on the rendering, and whatever scaling calculations that TextMeshPro is doing on scale change. Also manually disable TMP objects that are outside the camera frustrum. Definitely helps the GPU, but enabling/disabling gameobjects at runtime has a cost. I bet using ECS would have made this approach viable but I haven’t dug into that system quite yet and was on a deadline.

Far away text is now rendered as a point (There’s a quad mesh on each point in addition to TMP). Every frame the distance to camera is calculated for every point, which controls if it is rendered (or disabled if out of view) Also here, you can see the words colored by part of speech.
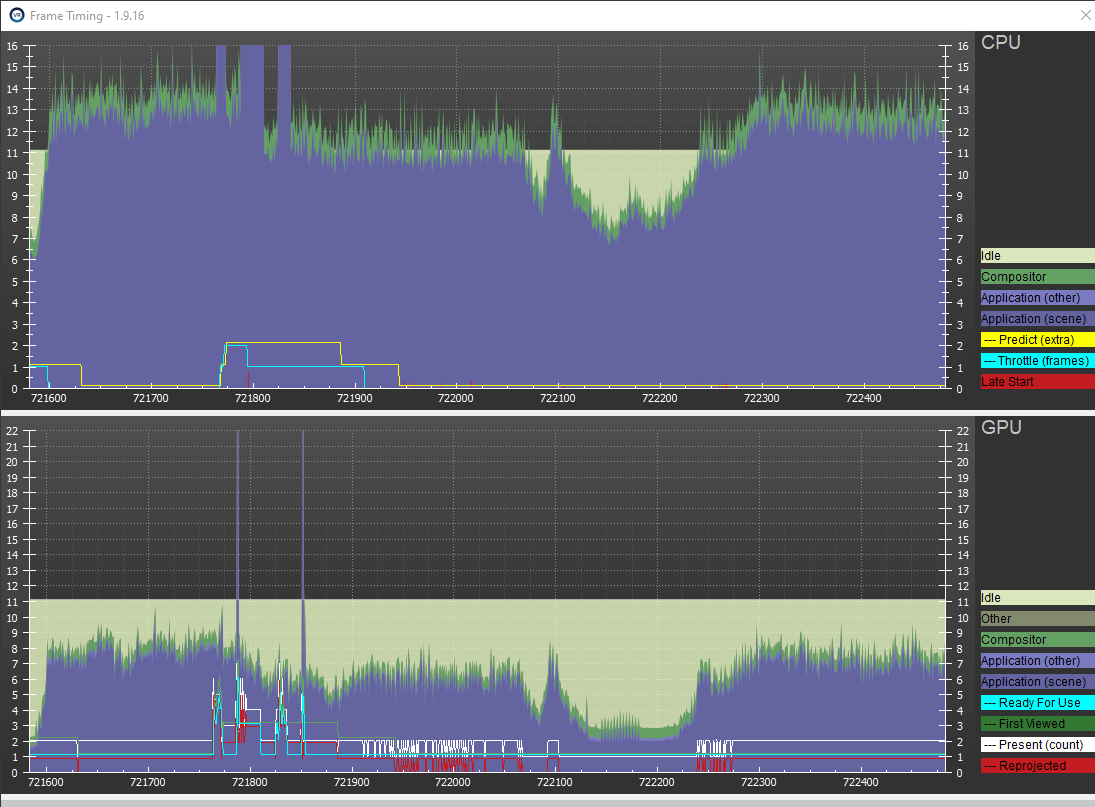
(SteamVR profile) Calculating all this stuff was really terrible for the CPU, even though the GPU was now happy (rendering less stuff, mostly points which batch!). I tried to batch Text Mesh Pro, but they explicitly disallow that in the shader {DisableBatching = True } and instance every material (not ideal). This also clogs up the CPU making 10k draw calls per frame.
So, we need to somehow:
- Not scale Text Mesh Pro (don’t want to change their source)
- Not move colliders
- Get the Text to batch, and use a single material
- Get the text to billboard in the shader
Colliders
Every word has a collider so that I can detect grab and laser-pointer select in VR.

This one is pretty easy. Create the colliders, put them in another space and never move them! Then, manually raycast/spherecast every frame to calculate intersections. But, transform the controller position into the other space, and then do the raycast/spherecast in the other space. First off though, create a Dictionary<Collider, WordPoint> to map each of my proxy colliders to the words that they represent quickly.
More precisely, the hand (controller) is in the word cloud, compute its local position in the word cloud, and use that as the local position in the collider cloud.
var handInCloudSpace = WordCloudTransform.InverseTransformPoint(RightCursorTransform.position);
var handDirInCloudSpace = WordCloudTransform.InverseTransformDirection(RightCursorTransform.forward);
var handInColliderSpace = ColliderTransform.transform.TransformPoint(handInCloudSpace);
var handDirInColliderSpace = ColliderTransform.transform.TransformDirection(handDirInCloudSpace);
int numHits = Physics.RaycastNonAlloc(new Ray(handInColliderSpace, handDirInColliderSpace), raycastRightHand, 10f);
Now I realize I need to bite the bullet and create a custom shader for the word cloud text if I wanted to get all my goals accomplished.
Custom Shaders Rant
When I first started Unity dev, I wanted to make a custom shader for everything because it made me feel badass and I could do anything I wanted. But then I realized:
- custom shaders make it much harder for your coworkers to collaborate
- nothing batches if everything’s got a custom shader
- they are liable to break with updates to Unity or changes in your rendering pipeline
So now I usually think, if you can do it in Unity with the Standard shader, do that. But desperate times call for desperate measures…
Custom Shader
First thing was to just render a TextMeshPro mesh with my new shader and see what it looked like. But where do I get the mesh? TMP created the meshes and UVs them dynamically based on its texture atlas for the font you’ve selected, so there’s no actual mesh asset. No problem, I just rip the mesh out at runtime:
MyMeshfilter.mesh = SomeOtherTextMeshPro.meshFilter.mesh
TextMeshPro mesh rendered with a default custom unlit shader.

So… why is it blocks? Our material doesn’t have a texture yet. Search “Atlas” in the project to find the same texture atlas the original mesh was using… and it kinda works.
Why does it look like weird (it’s a distance field…)? Maybe I should have stuck with the text mesh pro shader after all? Yeah… let’s just copy paste TextMeshPro/Mobile/Distance Field into here… perfect. Now I can get into what I actually wanted to do, billboard the text. Some googling gives me this little gem: (shoutout to Github user Spongert) and https://en.wikibooks.org/wiki/Cg_Programming/Unity/Billboards

float4 vPosition = mul(UNITY_MATRIX_P, mul(UNITY_MATRIX_MV, float4(0.0, 0.0, 0.0, 1.0)) + float4(vert.x, vert.y, vert.z, vert.w));
Which instead of transforming the vertex into clipspace, transforms the origin into viewspace. THEN it adds the vertex local position into that, and transforms into clipspace. This has the effect of keeping the mesh oriented to viewspace which is exactly what we want. The only problem is that if dynamic batching is enabled, you can’t assume that your vertices are actually in the local position of the object being rendered, because Unity will bake the gameobject transform into there. So we have to disable batching. Well damn, that’s not what I wanted.
Batching
If Unity’s not going to batch this and still keep the vertex in local space, then maybe it can be done manually. Take two text meshes at the origin and merge them. Then upload the position into the UV3 per-vertex data (TMP uses UV1 and UV2 for some reason). I also care about scale, so I’ll go ahead and pack that into the w component of UV3.
Then in the shader, the Model Matrix can be reconstructed per word, and the input.vertex vertices are still centered at the origin!
float3 uvPos = input.texcoord2.xyz;
float s = input.texcoord2.w
float4x4 Obj2World = float4x4(
s, 0, 0, uvPos.x,
0, s, 0, uvPos.y,
0, 0, s, uvPos.z,
0, 0, 0, 1);
Rotation doesn’t matter because it is staying oriented toward view space (billboarding). So this is a simple affine transform with only scale and translation. The inverse has an easy closed-form solution.
float4x4 World2Obj = float4x4(
1 / s, 0, 0, -uvPos.x / s,
0, 1 / s, 0, -uvPos.y / s,
0, 0, 1 / s, -uvPos.z / s,
0, 0, 0, 1);
So the vertex shader becomes (including the billboarding trick from above):
float4x4 custom_MV = mul(UNITY_MATRIX_V, Obj2World);
float4 vPosition = mul(UNITY_MATRIX_P, mul(custom_MV, float4(0, 0, 0, 1)) + vert * float4(scale, scale, 1, 1));
What this does:
-
- Create custom model matrix based on the UV data uploaded per vertex
- Transform 0,0,0 in the model space into view space
- Add the vertex position offset (times the scale)
- Project into clipspace
The other thing I need to do is add color per word, so I just upload that to the pervertex color channel.
I do this for all 5000 words, and they merge into one mesh with 100,000 vertices. (Use integer index format to exceed the 64k vert limitation) so it’s one draw call now!
At this point, I am using no TextMeshPro scripts, not moving or scaling any colliders, and billboarding all the words in the shader. But I can’t move the word cloud, because we only have local position available. So, take the trackball transform and upload the WorldToObject and ObjectToWorld matrices as a uniform shader parameter _WordCloudMatrix and _WordCloudMatrixInverse to the material.
So the vertex shader is now:
float4x4 customObj2World = mul(_WordCloudMatrix, Obj2World);
float4x4 custom_MV = mul(UNITY_MATRIX_V, customObj2World);
float4 vPosition = mul(UNITY_MATRIX_P, mul(custom_MV, float4(0, 0, 0, 1)) + vert * float4(scale, scale, 1, 1));
Profile
Now, I get exactly the same functionality with:
- One mesh
- One material
- One draw call
- One dynamic transform
- No dynamic colliders
Feeling good about this! Let’s check the profile.

Here’s my profiling test scene, using the new font from the client and the builtin postproc stack for the rest of their app. It’s got a good amount of text in view, and rendering pretty much the whole cloud.
It doesn’t show up on the profile. I enable and disable the mesh, even rotate it and scale it around.
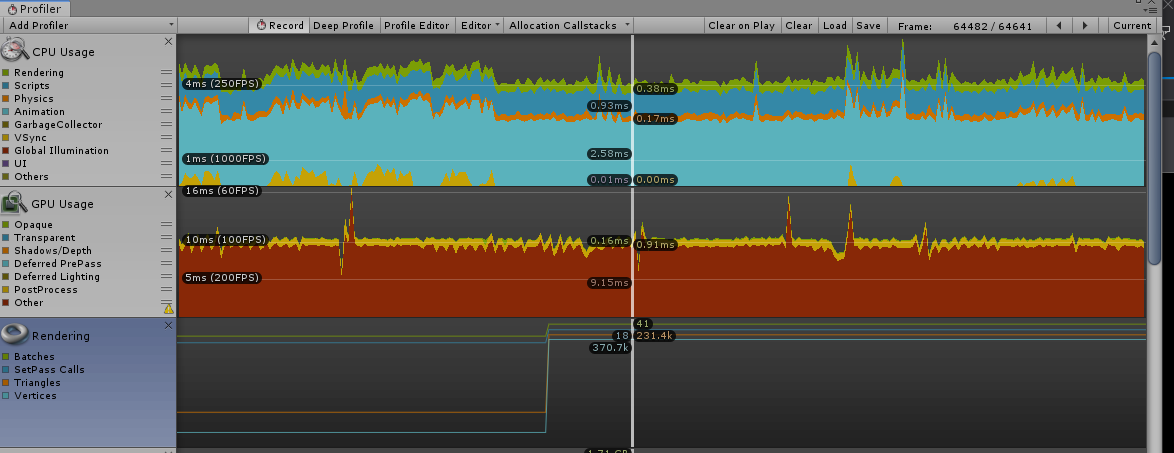
Left side of profile is my “empty scene”, with the same random 10ms “other”. Then you can see the spike on rendering (bottom) when I enable the word cloud. No difference. Maybe I should Look at it in a build.
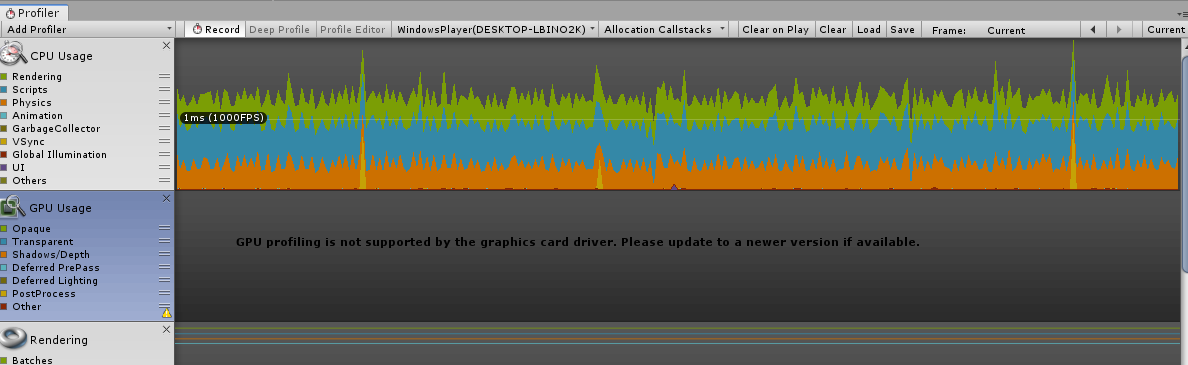
Ok so CPU is taking 1ms, that’s a good sign. But for some reason, i lost my GPU data in the build. Will have to look at why that happens later. Let’s check out the SteamVR profiler again.
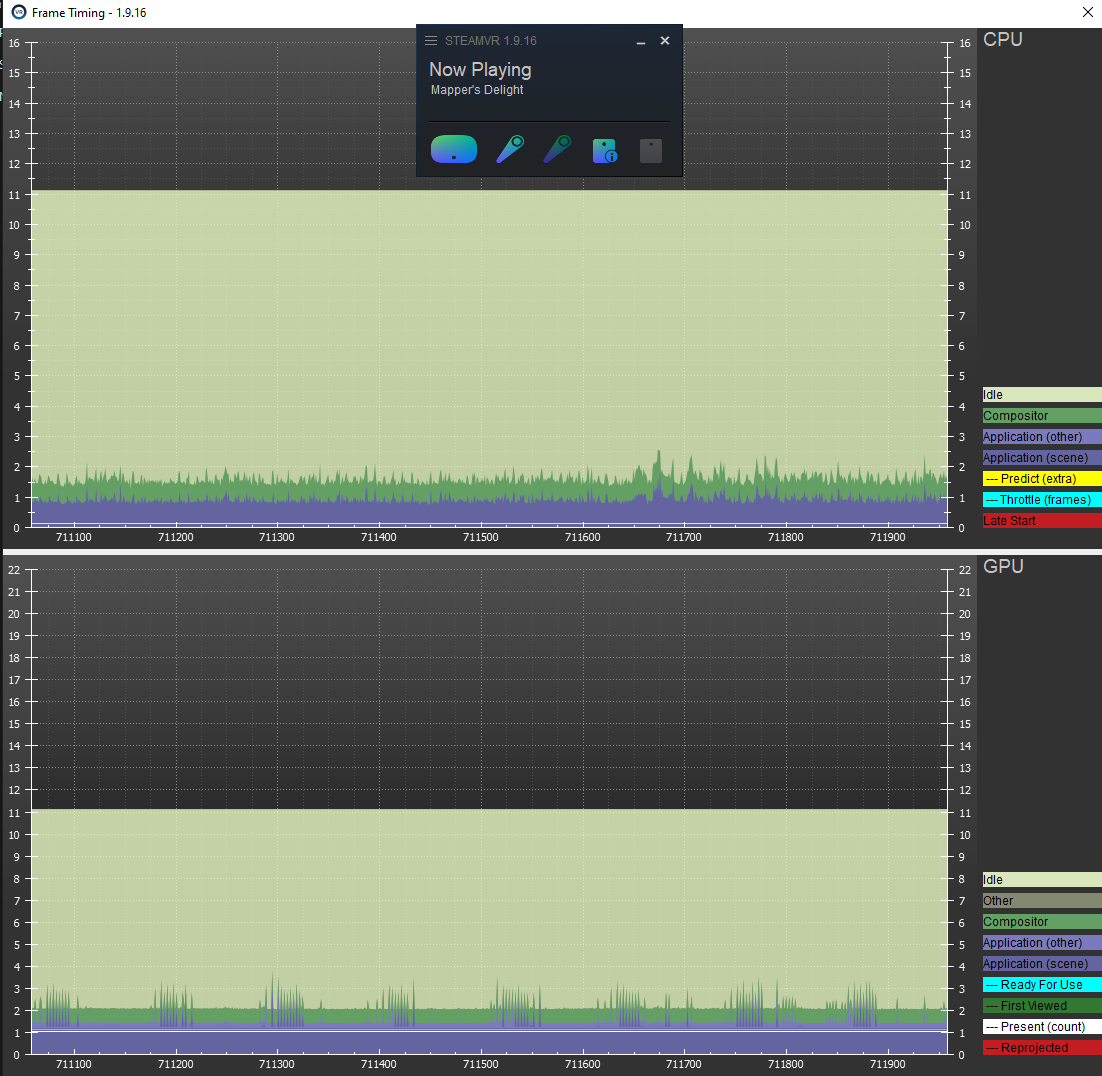
Hot damn! I have my 5K text/points rendering, totally interactively at a constant 1ms cpu and GPU. (originally was 30ms CPU and 16-20ms GPU). Time for a beer.
Point Rendering Transition
I skipped the part where I render points when the word gets far enough away.
Basically there is a second mesh exactly like the first merged text mesh, except each word is a quad. Still upload the color and local position/scale into the pervertex data. The shader is really similar.
Then add some scaling logic in the shader… since we have the per-word scale and create the model matrix on the fly per word, this can be dynamic. So use the builtin Unity shader uniform _WorldSpaceCameraPos and then compute the word position in world space (that’s why I needed to compute the inverse matrix above)
float objSpaceDistance = length(mul(customWorld2Object, float4(_WorldSpaceCameraPos, 1)).xyz);
float scale = length(customObj2World._m00_m01_m02) * v.texcoord2.w;
scale = lerp(0, scale, smoothstep(_FadeOutNear, _FadeOutFar, objSpaceDistance));
So there’s some more shader parameters, _FadeOutNear and _FadeOutFar, which control the fadeout-ness. Just invert the logic in the point shader vs the text mesh shader, so that the points fade in as the words fade out.
In theory, this could be all in the same original mesh with just a flag pervertex saying if it is part of the quad or the text. Or, make all the text character quads for each letter morph smoothly into a single point… but who has time for that.
Selection
Well, I still want to be able to select words, which is what I was doing earlier with the dumb version, but I was swapping materials to show if something was selected. That doesn’t work anymore because this is all one mesh. Luckily, I have a unique Identifier per word, which is its position in the cloud. So If I have detected a selection (using the collider setup and dictionary lookup above), then the position of the selected word is uploaded as another material property uniform.
bool selected = (length(_SelectedWordPos - uvPos.xyz) < 0.01);
Then something like:
scale *= lerp(1,2,selected);
color *= lerp(1,2,selected);
outlineWidth = lerp(0,1,selected);
Or whatever else you feel like doing. And bam! Super interactive. No CPU logic!
BONUS SECTION: Timelines
I also did some analysis of the word usage in the corpus over time.
If you click a word, it will generate this view of the frequency of each word each year.


interesting word cloud areas